Computadores do Google escreveram a legenda para uma foto e isso é revolucionário

Os computadores do Google agora tem um sistema de aprendizado automatizado que pode analisar imagens como esta acima e gerar legendas para elas. A frase usada para legendar esta imagem? “Uma pessoa pilota uma motocicleta em uma estrada de terra”. Pode não parecer muito, mas, na verdade, esta é uma realização e tanto.
A tirinha abaixo, do XKCD, ilustra bem este processo:

“‘Quando um usuário tira uma foto, o aplicativo deve checar se ele está em um parque nacional…’
‘Claro, é só usar um sistema de informação geográfica. Preciso de algumas horas.’
‘…e cheque se a foto é de um pássaro.’
‘Eu vou precisar de uma equipe de pesquisa e cinco anos.’
Em ciência da computação, pode ser difícil explicar a diferença entre o fácil e o virtualmente impossível.”
O resultado é bastante claro: identificar automaticamente imagens nas fotos é enganosamente difícil para os computadores. O quão enganoso? O texto da tirinha resume a história do pioneiro da inteligência artificial, Marvin Minsky, e sua tarefa de verão, agora renomada como infame.
Summer Vision Project
Em 1966, Minsky pediu que alguns de seus graduandos do Instituto de Tecnologia de Massachusetts para “passar o verão que conectando uma câmera a um computador e fazer com que o computador descrevesse o que a câmera viu.” Colega e antigo colaborador de Minsky, Seymour Papert, elaborou um plano de ataque no qual explica que a tarefa foi escolhida “porque pode ser dividida em sub-problemas, permitindo que indivíduos funcionem independentemente e ainda participem na construção de um sistema complexo o suficiente para ser um verdadeiro marco no desenvolvimento do ‘padrão de reconhecimento'”. Em outras palavras, o trabalho parecia difícil, mas factível.
Quase meio século depois, cursos universitários em visão computacional ainda estão estruturados em torno dos obstáculos que os alunos de Minsky encontraram naquele verão de 1966 – muitos ainda são um desafio; outros permanecem inteiramente desconhecidos. “É difícil dizer exatamente o que torna a visão difícil já que ainda não temos uma solução”, diz a introdução do curso do MIT sobre temas fundamentais e avançados em visão computacional.
Dito isso, dois dos desafios mais amplos que a visão computacional enfrenta são claros. O primeiro dele é a estrutura da entrada das informações, o segundo é a estrutura da saída desejada.
Transformando imagens em palavras
Em um post recente no blog do Google Research, os cientistas Oriol Vinyals, Alexander Toshev, Samy Bengio e Dumitru Erhan descreveram a sua abordagem para o enigma da entrada/saída. “Muitos esforços para construir descrições naturais de imagens geradas por computador propõem combinar técnicas atuais do estado da arte, tanto na visão de computador quanto no processamento de linguagem natural para formar uma abordagem descritiva da imagem completa”, explicam. “Mas e se, ao invés disso, nós fundíssemos modelos recentes de visão computacional e de linguagem em um único sistema treinado em conjunto, pegássemos uma imagem e produzíssemos diretamente uma sequência de leitura humana de palavras para descrevê-la?”
O resultado é que Vinyals e seus colegas estão na vanguarda de tradução automática para transformar imagens digitais (a entrada) em linguagem que soe natural (a saída).
O que é impressionante sobre essa saída é o quão descritiva ela é. Ele faz mais do que identificar o objeto (ou objetos) em uma imagem, algo que havia sido feito no passado (há dois anos, por exemplo, pesquisadores do Google desenvolveram um software de reconhecimento de imagem que poderia ser treinado a reconhecer as fotos de gatos). Em vez disso, a saída descreve as relações entre os objetos, com uma descrição holística do que está realmente acontecendo na cena. O resultado é uma legenda que pode acabar sendo surpreendentemente precisa, mesmo quando comparada com legendas fornecidas por seres humanos:

Legenda do computador: “Duas pizzas em cima de um fogão com forno.” / Legenda do ser humano: “Três tipos diferentes de pizza em cima de um fogão.”
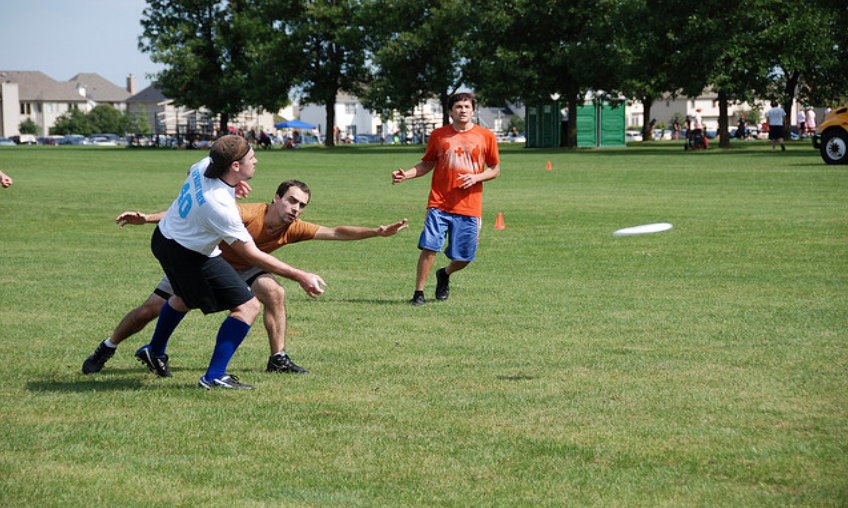
Legenda do computador: “Um grupo de jovens jogam um jogo de frisbee.” / Legenda do ser humano: “Um grupo de homens jogando frisbee no parque.”
Como isso é possível? O sistema da equipe depende de avanços recentes em dois tipos de redes neurais. O primeiro é estruturado para encontrar sentido nas imagens; o segundo, para gerar linguagem.
RNC e RNR
Como seu nome sugere, as redes neurais se inspiram no projeto da estrutura organizacional de neurônios no nosso cérebro. O identificador profundo de imagens usado por Vinyals e sua equipe, batizado Rede Neural Convolucional (RNC), conta com múltiplas camadas de identificação de padrões. A primeira camada analisa diretamente a imagem e escolhe características de baixo nível como a orientação de linhas ou padrões de luz e escuridão. Acima de cada camada está outra que tenta dar sentido a padrões da camada abaixo dela. À medida que se avança nesta pilha, a rede neural começa a entender padrões cada vez mais abstratas. A orientação dos pixels identificados na primeira camada pode ser reconhecida com uma camada superior, tal como uma linha curva. Ainda maior, outra camada pode reconhecer a curva como a forma de orelha de um gato. Eventualmente, chega-se a uma camada que efetivamente diz que “isto parece ser uma imagem de um gato.”
O que Vinyals e sua equipe têm feito é combinar os poderes de identificação de imagem profunda de um RNC com as habilidades de geração de linguagem de Redes Neurais Recorrentes (RNR). Considere, por exemplo, a word2vec, uma ferramenta de tradução automática que transforma palavras, frases e sentenças em “vetores de alta dimensão” – o que é apenas um nome fantasia para vetores cujas características são definidas por um grande número de parâmetros. Se você acha isso difícil de conceber, os cientistas da computação John Hopcroft e Ravi Kannan descreveram um cenário envolvendo vetores no spaços altamente dimensionais que podem ser úteis.
“Considere representar um documento por um vector no qual cada componente corresponde ao número de ocorrências de uma palavra particular no documento. O idioma inglês tem cerca de 25 mil palavras. Assim, um documento desse tipo é representado por um vetor de 25 mil dimensões.”
Um RNC gerador de linguagem pode transformar, por exemplo, uma frase francesa em uma representação do vetor em “francês espacial.” Desenhando esses vetores em um espaço dimensional alto o suficiente, o sistema pode representar a forma como as palavras, frases e sentenças são semelhantes e diferentes umas das outras. Alimente esta representação do vetor com um segundo RNC e você pode gerar uma frase em alemão e submeter as palavras e frases constituintes a análises comparativas semelhantes.
O que Vinyals e sua equipe fazem é substituir o primeiro RNR (o RNR do francês espacial) e suas palavras de entrada com uma RNC profunda treinada para classificar objetos em imagens. “Normalmente, a última camada da RNC atribui a probabilidade de que cada objeto possa estar na imagem”, conta a equipe. “Porém, se essa camada final for removida, é possível alimentar a rica codificação da RNC da imagem em uma RNR projetada para produzir frases. Podemos, então, treinar todo o sistema diretamente nas imagens e suas legendas, de modo que maximizamos a probabilidade de que as descrições produzidas se encaixem melhor com as descrições de treinamento para cada imagem.”
Viu como não é nem um pouco simples?
O resultado é um programa de software que pode aprender a identificar padrões em imagens. Vinyals e sua equipe treinaram seu sistema com conjuntos de dados de imagens digitais que anteriormente tinham sido legendados por seres humanos com frases descritivas. Em seguida, eles pediram que o seu sistema descrevesse as imagens que nunca tinha visto antes.
As descrições não são sempre 100% exatas, mas o sistema consegue ser impressionante, mesmo quando ele dá alguma escorregadela. Em uma imagem de um garotinho cochichando no ouvido de uma menina de touca cor-de-rosa, por exemplo, a legenda automática dizia “Uma garotinha com um chapéu rosa está fazendo bolinhas de sabão”. Já uma placa de “proibido estacionar” cheia de adesivos foi descrita como “Um refrigerador cheio de comida e bebidas”.
Claro, muitos das vaciladas cometidas pelo modelo são engraçados, mas também são simpáticos. Seus erros são charmosos, de forma semelhante às observações quase-certas-mas-ainda-engraçadamente-erradas feitas por crianças (por exemplo, descrever uma scooter rosa como uma “motocicleta vermelha”, ou um cão, obviamente estático, como “saltando para pegar um frisbee”). É como observar a máquina em um estágio intermediário de seu desenvolvimento intelectual – e, em um sentido muito real, é o que estamos fazendo.
Estes resultados, até agora, parecem promissores. Medido quantitativamente, o programa da Google Research foi capaz de descrever objetos e suas relações em mais de duas vezes a precisão das tecnologias anteriores. Em um futuro próximo, este tipo de tecnologia pode ser uma bênção para as pessoas com deficiência visual ou até em regiões remotas, que nem sempre podem fazer o download de imagens grandes por terem conexões muito lentas.
E, claro, há a própria busca no Google. Quando você procura por imagens hoje, você provavelmente o faz em palavras-chave, em vez de frases que soam naturais. Este novo sistema poderia um dia mudar a nossa forma de busca de “cachorrinho tigela gif” para “Filhote de cachorro muito fofo luta para sair de uma tigela de metal”. [io9, Google Research Blog]

